

Accelerating LoRA Fine-tuning with Custom CUDA Kernels and Autograd Functions


We're excited to announce a performance improvement to Axolotl's LoRA and QLoRA fine-tuning capabilities. Taking inspiration from the work done by the Unsloth team, we've implemented custom CUDA kernels and PyTorch autograd functions that improve both the speed and peak VRAM usage of LoRA fine-tuning workflows.
What's New?
Our optimization efforts focus on two key areas that frequently become bottlenecks during training. First, we've added custom Triton kernels for SwiGLU and GEGLU activation functions, which are crucial operations in modern LLMs. Second, we've implemented custom torch.autograd functions for LoRA MLP and attention mechanisms, allowing us to fuse operations and reuse tensors more efficiently during both forward and backward passes.
These optimizations are particularly valuable for Axolotl users working with popular model architectures (including, but not limited to, the Llama, Mistral, Qwen2, and Gemma families of models). Whether using a single GPU or leveraging multiple GPUs with DDP (Distributed Data Parallel) or DeepSpeed, these improvements can help you train more efficiently.
Getting Started
Enabling these optimizations in your existing Axolotl workflows is straightforward. Simply add the following parameters to your config YAML file:
lora_mlp_kernel: true
lora_qkv_kernel: true
lora_o_kernel: trueBenchmarks
The following benchmark results were obtained on an instance with 1 x H100 SXM GPU from Runpod. The basic script used for benchmarking can be found here. Models are loaded with parameters in torch.float16 dtype.
Please note that these results were obtained by averaging forward and backward pass timings / memory usage over 30 trials each (after a warmup phase), so there is some degree of variability, and that results may differ on different hardware (CPU / GPU models and configuration).
HuggingFaceTB/SmolLM2-135M
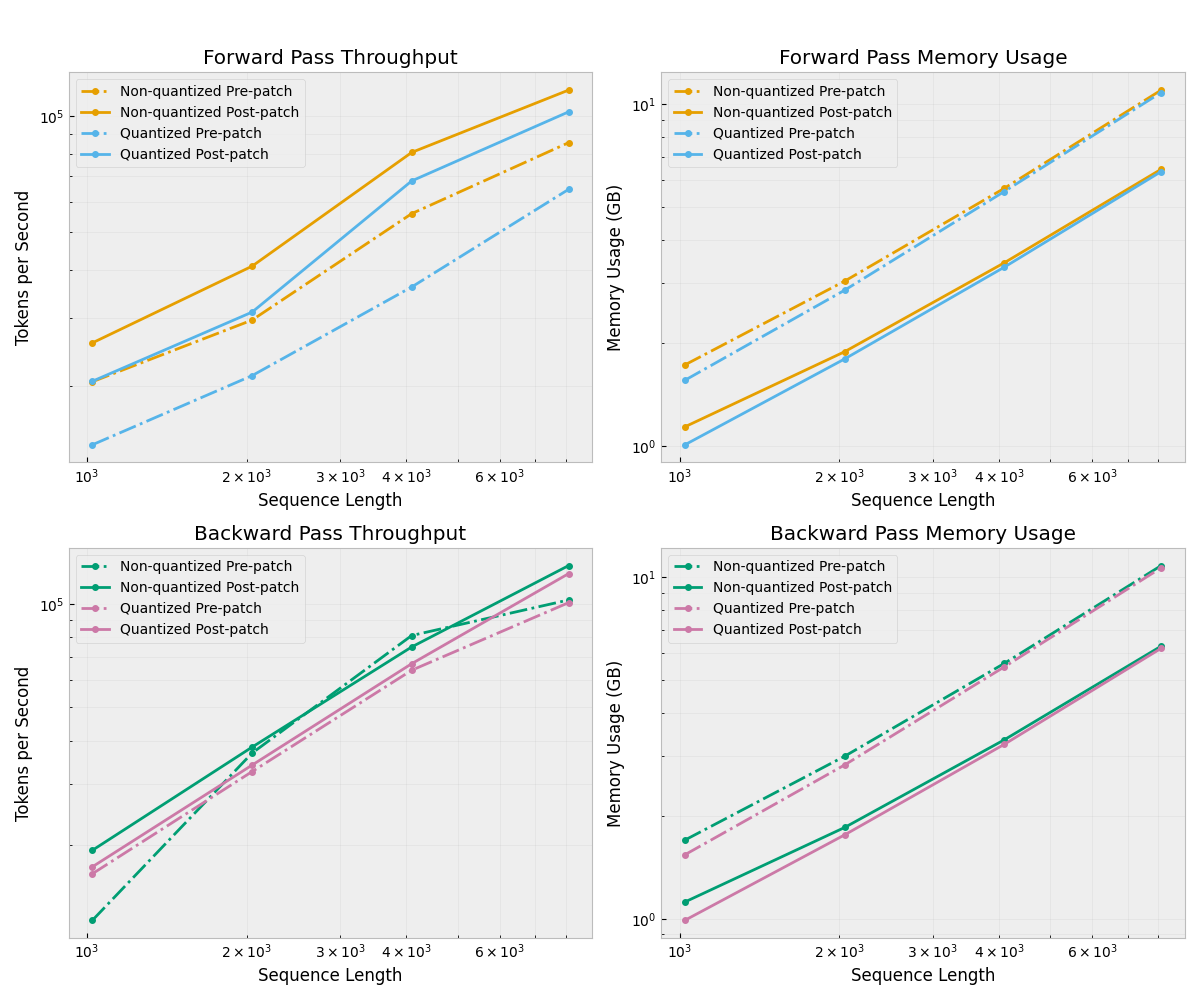
Forward pass:
Average speedup: 1.48x
Average memory savings: 38.2%
Average throughput gain: 47.9%
Backward pass:
Average speedup: 1.15x
Average memory savings: 38.9%
Average throughput gain: 14.7%
HuggingFaceTB/SmolLM2-1.7B
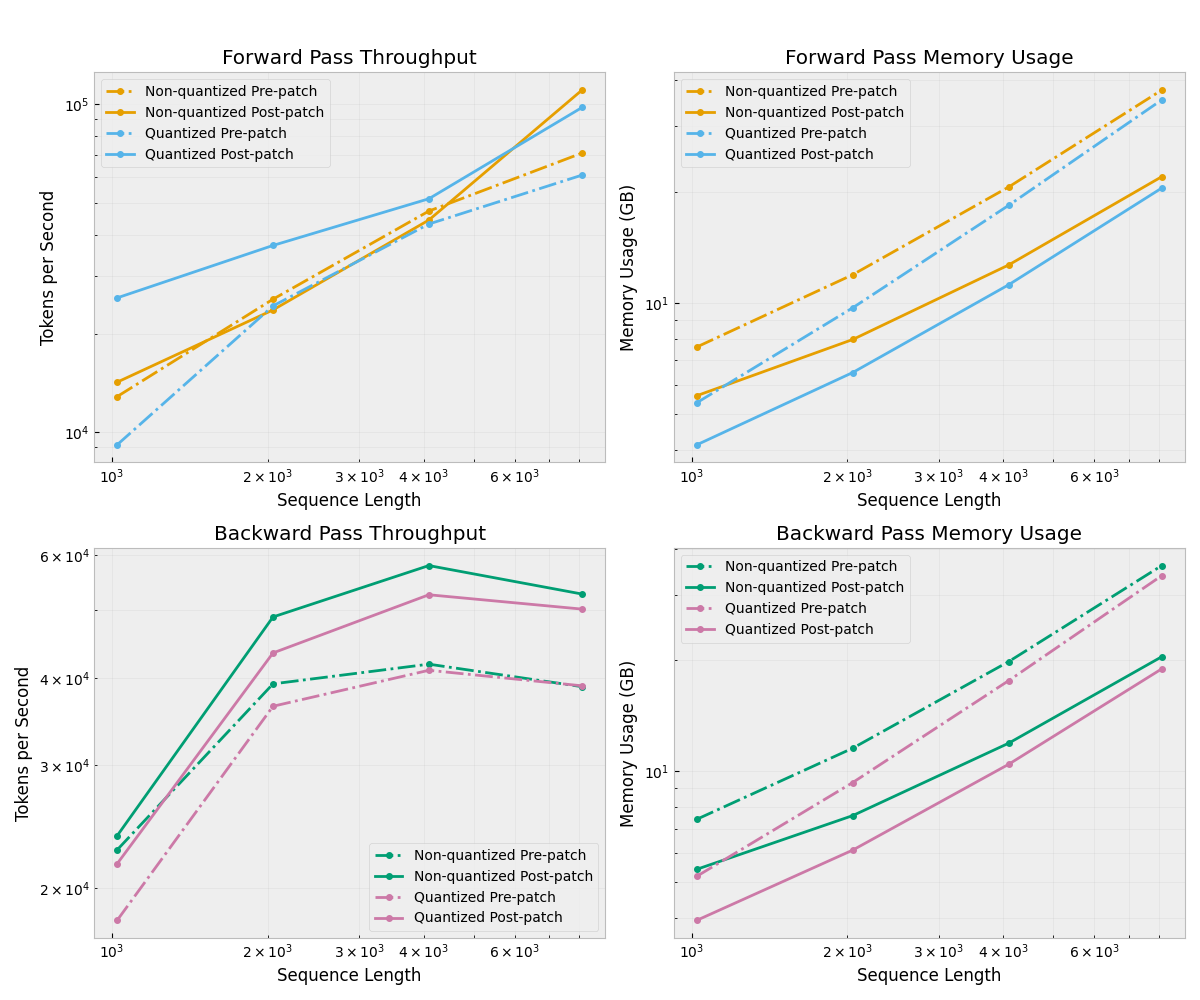
Forward pass:
Average speedup: 1.46x
Average memory savings: 34.6%
Average throughput gain: 45.8%
Backward pass:
Average speedup: 1.25x
Average memory savings: 35.9%
Average throughput gain: 25.1%
NousResearch/Meta-Llama-3.1-8B
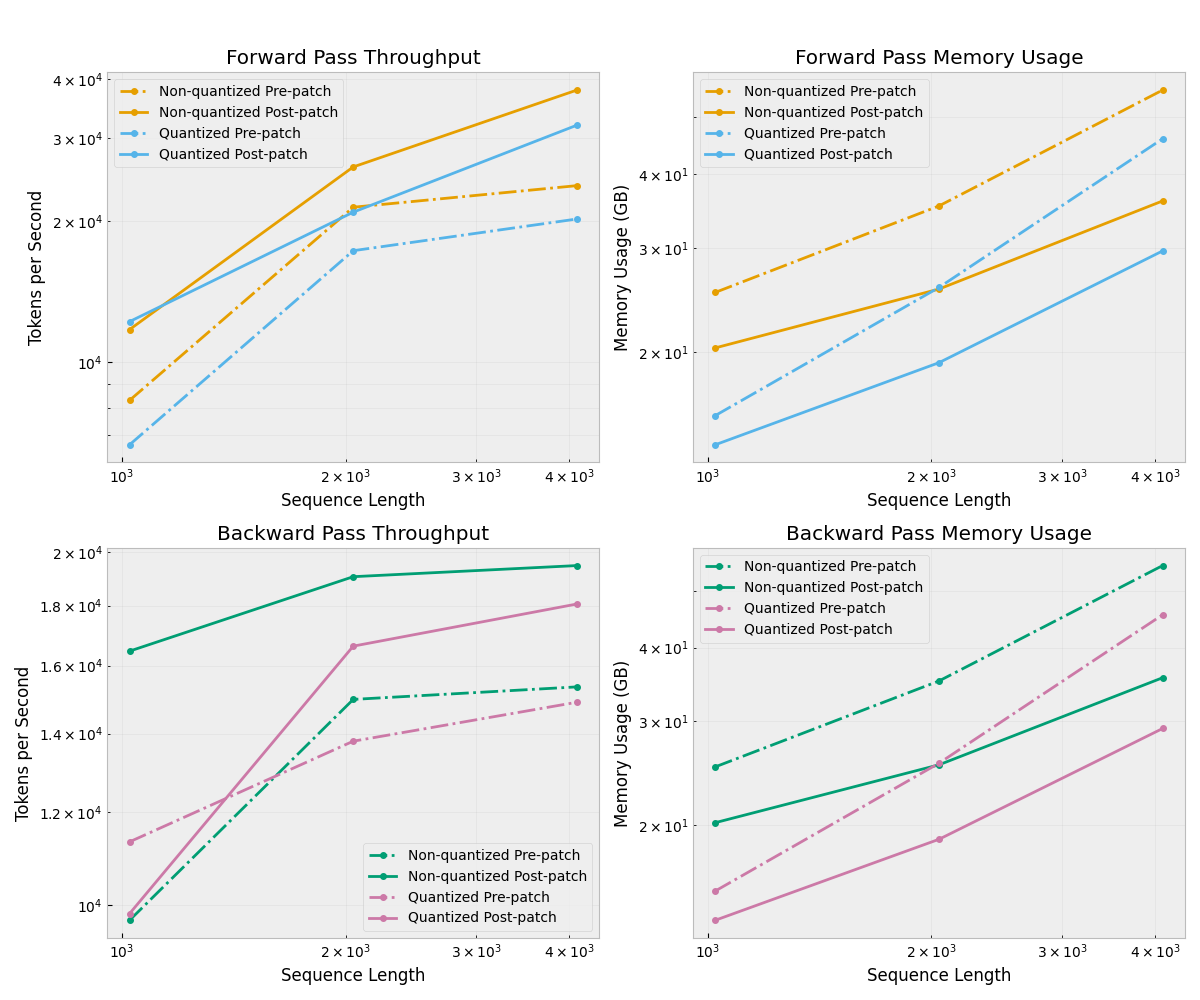
Forward pass:
Average speedup: 1.48x
Average memory savings: 25.7%
Average throughput gain: 47.5%
Backward pass:
Average speedup: 1.25x
Average memory savings: 25.9%
Average throughput gain: 25.4%
Technical Details
The core of these optimizations lies in our custom autograd functions. For MLPs, we fuse the LoRA and base weight computations into a single forward and backward pass. In the attention layers, we optimize the query, key, and value projections along with the output projection by monkey-patching parts of the transformers attention implementations with our custom autograd functions.
The Triton kernels powering our activation functions are designed to handle both forward and backward passes efficiently, working together with the custom autograd functions to minimize memory movement and maximize throughput.
Limitations
Hardware requirements: You'll need NVIDIA or AMD GPUs to take advantage of the Triton kernels. Set TORCH_ROCM_AOTRITON_ENABLE_EXPERIMENTAL=1 to enable memory-efficient attention on AMD GPUs.
Model constraints: These optimizations currently require LoRA adapters without dropout layers or bias terms. This may slightly limit model expressivity / performance.
Architecture support: Our current implementation supports several major model architectures (including, but not limited to,
llama,mistral,mixtral,qwen2,gemma, andgemma2), with plans to expand coverage in future releases.
Future Work
Adding support for additional model architectures
Adding compatibility with FSDP for multi-GPU training
Note: these kernels work with DeepSpeed v3 already!
Adding support for dropout and bias terms without sacrificing performance
Identifying opportunities for additional operator fusions / tensor re-use
Try It Out!
If you're already using Axolotl for your fine-tunes, updating your config to use these optimizations is all you need to do. For new users, check out our documentation for setup instructions and best practices.
We're excited to see how these optimizations will help accelerate your training workflows. If you encounter any issues or have suggestions for improvements, please don't hesitate to open an issue or submit a PR on our GitHub repository.